Чтение файла в обратном порядке на PHP
В отличие от прямого чтения файла, обратное чтение имеет особенности, о которых не задумываешься, пока не столкнешься с ними на практике. Это достаточно редкая задача, поскольку разработчику в большинстве ситуаций приходится работать с данными из БД, которые уже хорошо структурированы и отсортированы. Но иногда можно столкнуться с такой уникальной ситуацией (или даже создать ее).
Предпосылки возникновения задачи
Мне потребовалось анализировать статистику запросов, которую я логировал в файлы, для подсчета актуального количества в интервале N дней. Логи я решил хранить в файлах по двум причинам:
- Исключить мусор в БД
- Ограниченные ресурсы VPS
Изучив документацию PHP, я понял, что привычный fgets в этой ситуации не поможет, и придется использовать ряд других методов, которые в комбинации дадут ожидаемый результат.
Особенности обратного чтения
Предположим, у нас есть следующий файл:
$ echo -e "Message 1\nMessage 2\nMessage 3\nMessage 4" > test.log $ cat test.log Message 1 Message 2 Message 3 Message 4 $ du -b test.log 40 test.log # Размер файла: 40 байт
Когда мы читаем файл построчно, знакомый всем метод fgets самостоятельно определяет символ переноса и возвращает готовую строку "Message 1". Но при обратном чтении такой подход не сработает, поскольку файловый указатель смещается в конец файла и начинает двигаться к началу по одному байту.
Пример порядка символов и байт при обратном чтении (для последней строки):
Char | Byte
----------
\n | 40 # Символ переноса строки
4 | 39 # Последний символ строки
| 38 # Пробел
e | 37
g | 36
a | 35
s | 34
s | 33
e | 32
M | 31 # Первый символ строки
Ключевой момент здесь – сборка строки и контроль символа переноса \n в контексте предыдущей строки.
При стандартном (прямом) чтении файла мы тоже можем двигаться по символам и собирать строку, но обычно на практике так не делают, а используют готовый метод
fgets.
Базовые примеры кода
Для чтения файлов малого размера существуют более простые и короткие решения. В данном разделе представлены расширенные варианты для наглядности и с целью масштабирования решения под большие объемы данных.
Посимвольное чтение
Базовый пример, демонстрирующий обратное чтение файла. Ключевые моменты:
- Контроль смещения файлового указателя
- Посимвольное чтение
- Контроль символа переноса и сборка строки
$lines = [];
$stream = fopen("test.log", "r");
fseek($stream, 0, SEEK_END); // Перемещаем указатель в конец файла
$position = ftell($stream); // Запоминаем позицию указателя
$line = '';
while ($position > 0) {
fseek($stream, --$position); // Смещаем указатель на один байт назад
$char = fgetc($stream); // Читаем символ
if ($char == "\n") {
$lines[] = $line;
$line = '';
} else {
$line = $char . $line; // Собираем строку (добавляем символ в начало)
}
}
// Добавляем последнюю строку (если файл не заканчивается переносом)
if ($line !== '') {
$lines[] = $line;
}
fclose($stream);
var_dump($lines);
// array(4) {
// [0]=> string(9) "Message 4"
// [1]=> string(9) "Message 3"
// [2]=> string(9) "Message 2"
// [3]=> string(9) "Message 1"
// }
Чтение чанками
При работе с файлами большого объема и ограниченных ресурсах предыдущий подход становится неэффективным из-за снижения производительности. В таком случае логично перейти к чтению файла чанками (блоками), что позволяет контролировать количество операций ввода-вывода и оптимизировать процесс.
$lines = [];
$stream = fopen('test.log', 'r');
fseek($stream, 0, SEEK_END);
$position = ftell($stream);
$buffer = '';
while ($position > 0) {
// Определяем размер текущего чанка (не больше 1KB и не больше оставшихся данных)
$chunkSize = min(1024, $position);
$position -= $chunkSize;
fseek($stream, $position);
$chunk = fread($stream, $chunkSize); // Читаем чанк
// Добавляем чанк в начало буфера
$buffer = $chunk . $buffer;
// Обрабатываем все найденные строки в буфере
while (($newlinePos = strrpos($buffer, "\n")) !== false) {
$line = substr($buffer, $newlinePos + 1);
if ($line !== '') {
$lines[] = $line;
}
$buffer = substr($buffer, 0, $newlinePos);
}
}
// Добавляем последнюю строку (начало файла)
if ($buffer !== '') {
$lines[] = $buffer;
}
fclose($stream);
Пример кода из реального проекта
Представленный ниже класс используется в проекте для обратного чтения лог-файлов.
Generator был выбран для удобства переиспользования кода и оптимизации памяти. Можно также использовать SplFileObject класс вместо нативных функций, но в рамках проекта акцент был сделан на самописный вариант для большей гибкости.
declare(strict_types=1);
namespace App\SPL;
use App\Interfaces\FileReaderInterface;
use Generator;
class ReverseFileReader implements FileReaderInterface
{
private const CHUNK_SIZE = 8192; // 8KB
private string $path;
public function __construct(string $path)
{
$this->path = $path;
}
public function read(): Generator
{
if (!is_readable($this->path)) {
return;
}
$stream = fopen($this->path, 'rb');
$fileSize = filesize($this->path);
if ($fileSize === 0) {
fclose($stream);
return;
}
$buffer = '';
$position = $fileSize;
try {
while ($position > 0) {
$chunkSize = min(self::CHUNK_SIZE, $position);
$position -= $chunkSize;
// Читаем очередной чанк
fseek($stream, $position);
$chunk = fread($stream, $chunkSize);
// Добавляем чанк в начало буфера
$buffer = $chunk . $buffer;
// Извлекаем все полные строки из буфера
while (($newlinePos = strrpos($buffer, "\n")) !== false) {
$line = substr($buffer, $newlinePos + 1);
if ($line !== '') {
yield $line;
}
$buffer = substr($buffer, 0, $newlinePos);
}
}
// Последняя строка (начало файла)
if ($buffer !== '') {
yield $buffer;
}
} finally {
fclose($stream);
}
}
}
Пример реализации показывает перебор доступных лог-файлов (сформированных по годам) и подсчет логов в интервале N последних дней:
public function countByDays(int $value): array
{
$timestampBefore = strtotime("-{$value} days 00:00:00");
$logPath = $this->service->getLogPath();
$result = [];
foreach ($this->service->getLogFiles() as $logFile) {
$filePath = storage_path("{$logPath}/{$logFile}");
$fileReader = new ReverseFileReader($filePath);
foreach ($fileReader->read() as $line) {
$timestamp = $this->extractTimestamp($line);
if (is_null($timestamp)) {
continue;
}
// Если запись слишком старая, прекращаем обработку
if ($timestamp < $timestampBefore) {
break 2; // Выходим из обоих циклов
}
$dateKey = date('Y-m-d', $timestamp);
$result[$dateKey] = ($result[$dateKey] ?? 0) + 1;
}
}
ksort($result);
return $result;
}
Сравнение производительности
Ниже представлены результаты замеров производительности для двух подходов из базовых примеров. Сделал в проекте два тестовых класса:
ReverseFileReaderByChar.phpReverseFileReaderByChunk.php
Метрики из консоли:
PHP Version: 7.4.33
Memory Limit: 128M
Array
(
[class] => ReverseFileReaderByChar
[file] => storage/app/private/views_log/2022.log
[file_size] => 11739378
[file_size_human] => 11.2 MB
[lines] => 77685
[avg_line_length] => 150.12 bytes
[time] => 30.3312
[time_human] => 30.3312 s
[memory_used] => 296
[memory_used_human] => 296 B
[memory_peak] => 465512
[memory_peak_human] => 454.6 KB
[speed] => 2561
[speed_human] => 2,561 lines/sec
[throughput] => 0.37 MB/s
)
Array
(
[class] => ReverseFileReaderByChunk
[file] => storage/app/private/views_log/2022.log
[file_size] => 11739378
[file_size_human] => 11.2 MB
[chunk_size] => 8192
[lines] => 77685
[avg_line_length] => 150.12 bytes
[time] => 0.1351
[time_human] => 135.1 ms
[memory_used] => 296
[memory_used_human] => 296 B
[memory_peak] => 465512
[memory_peak_human] => 454.6 KB
[speed] => 575019
[speed_human] => 575,019 lines/sec
[throughput] => 82.87 MB/s
)
Почему чанк 8 KB? В моем случае дает оптимальный баланс между скоростью и памятью (в диапазоне 4-8-16 KB).
| Класс | Время | Строк/сек | Пропускная способность |
|---|---|---|---|
| ReverseFileReaderByChar | 30.33 сек | 2,561 | 0.37 MB/s |
| ReverseFileReaderByChunk (8KB) | 0.1351 сек | 575,019 | 82.87 MB/s |
Ключевой результат: оптимизация с чанками ускорила обработку в 225 раз при том же потреблении памяти.
Метрики из браузера:
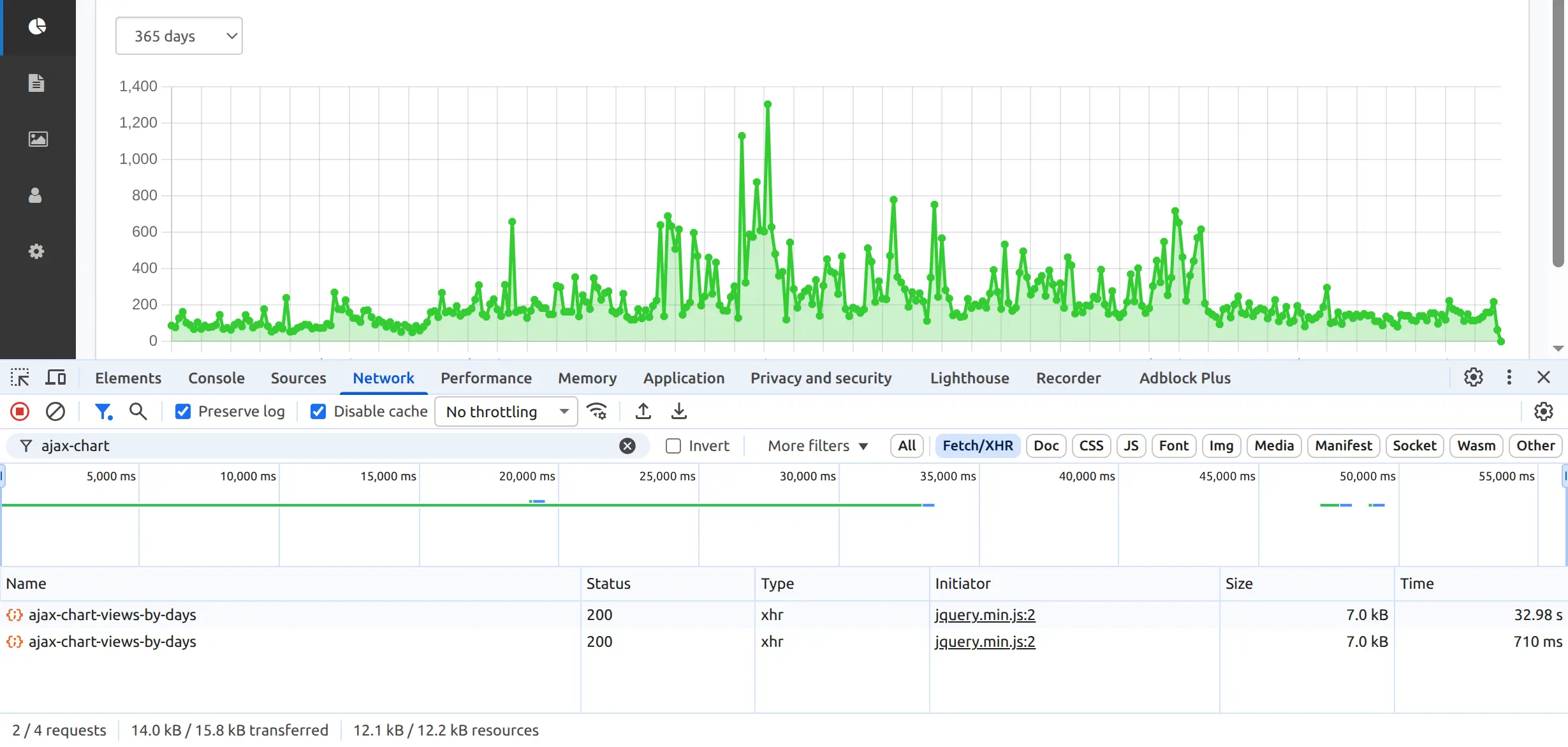
Вариант с чанками вполне справляется с поставленной задачей даже без дополнительного кеширования. Однако это справедливо только для текущего объема данных, где один годовой файл с логами не превышает ~10–12 MB и длина строки ~150 B. Для более крупных файлов потребуется своя оптимизация, например:
- Увеличение размера чанка
- Параллельная обработка
- Индексирование позиций строк
Или смена алгоритма парсинга...
Источники и ссылки
- Функции файловой системы – Руководство по PHP
- Генераторы – Руководство по PHP
- Класс SplFileObject – Руководство по PHP